Cybera Data Science Fellowship: Building a recommender system.
04 October 2021
Disclosure:
The content below is aimed to share my experience of building the backbone of a
reinforcement learning model during the Cybera DataScience Fellowship with
HockeyAI. It is not intended to offer a detailed explanation of Markov Decission
Processes. Snippets and plots displayed in this blog post belong to HockeyAI.
This post was written upon approval of Elliott Sheen from HockeyAI.
In the Cybera Data Science Fellowship, I worked with HockeyAI (Actionable Insight) to build a recommender system for student-athletes using ML and AI. We were interested in answering the following question: What is the best possible career path for a student-athlete interested in playing in the professional hockey leagues in North America?
For example, imagine you are 14 years old, and you are currently playing in the under-15 (U15) league. Since you are interested in playing in the professional hockey leagues, reaching the AHL or the NHL is paramount in your career. Because the best possible career path depends on your age, geographical location, performance in previous seasons, among other factors, our interest is to build a recommender system that optimizes your career path to help you reach the professional hockey leagues.
In the following sections, I offer some details of the approach we followed, some points to consider to build our RL model with a bit of the theory behind it, possible next steps, and my deliverables during the fellowship.
Approach
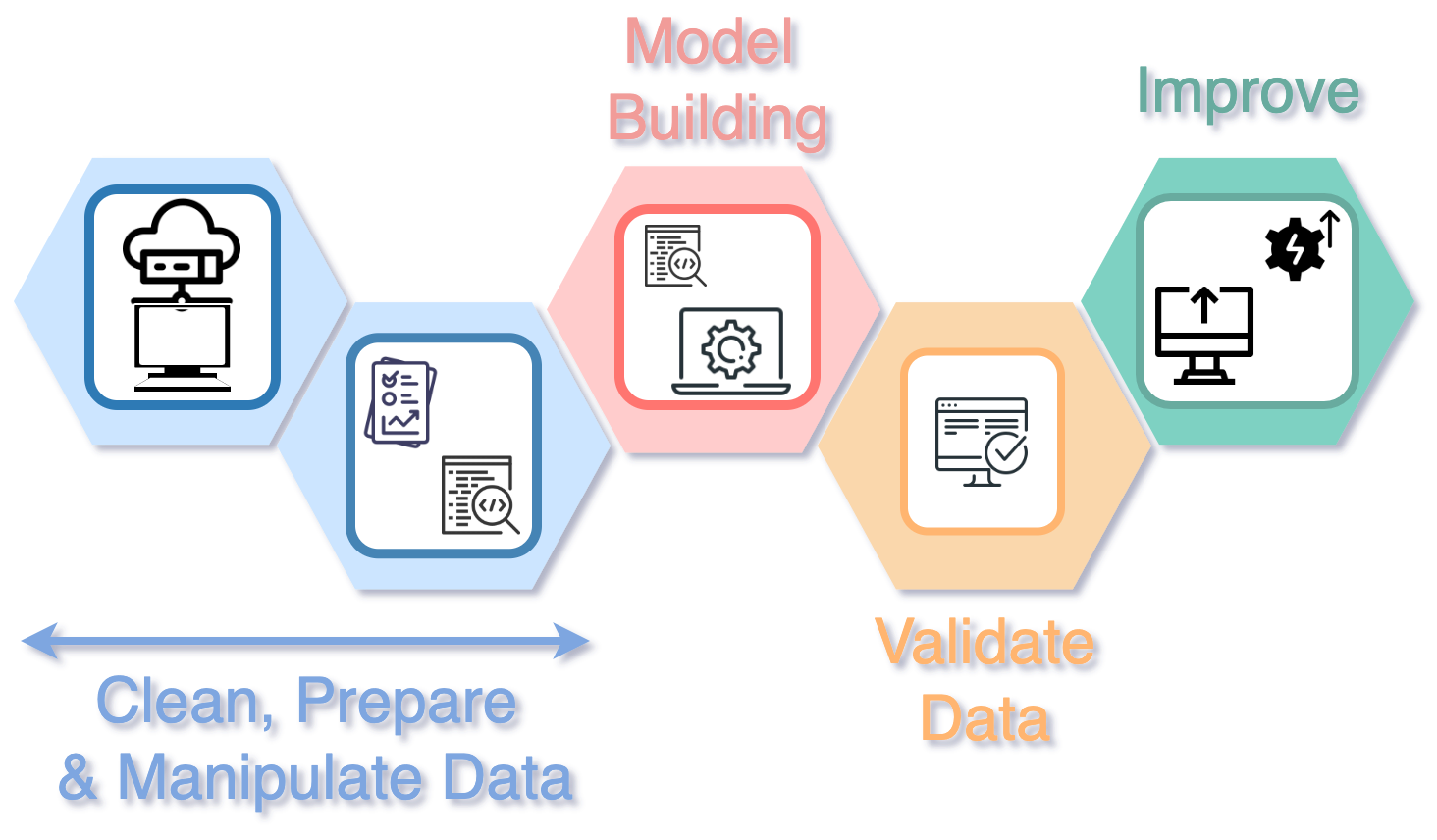
In this project, we followed the Agile methodology in combination with a standard Data Science workflow, as shown in the figure above. Since this was a remote position, we also used Docker to deploy the JupyterLab containers in a private cloud. In this way we guarantee all the members of the team work in the same virtual environment. Given the timeline of our project, my work was focused on the first two steps: data cleaning and model building.
For model building, I opted for a Reinforcement Learning (RL) approach. In contrast to unsupervised learning models, RL aims to maximize the reward of the agent instead of finding similarities and differences between data points. I opted for this model considering two main aspects: first, the ability of RL models to optimize rewards, and second, because our goal with HockeyAI is to optimize rewards of student-athletes to reach professional hockey leagues.
Markov Decision Processes
In Markov Decision Processes (MDP) there is an agent who interacts with an environment. The environment, in return, provides rewards. Based on this reward, the agent changes its state, and therefore new decisions taken by the agent will be influenced by the environment.
The following diagram summarizes a MDP applicable to Hockey AI:
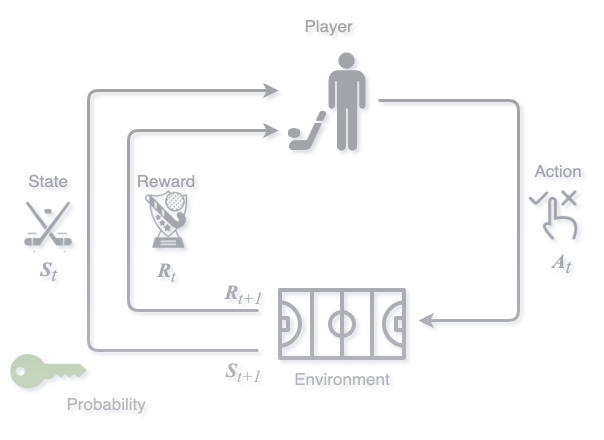
Player
The player (Agent) interacts with the environment by actions (𝐴), and receives rewards based on them. At each step (𝑡), the player executes an action, 𝐴𝑡.
Environment
The environment offers rewards (𝑅𝑡) and set a new state based on the actions of the player (𝐴𝑡). Hence, the environment receives the action (𝐴𝑡) and generates a new reward for the player, 𝑅𝑡+1.
State
The state of the player at a specific t in a given environment (𝑆𝑡). When the player executes an action, the environment gives the agent a reward, and a new state for the agent is set (𝑆𝑡+1).
Reward
Reward is the numerical value that the player receives when executing an action at a given state(s) and in a given environment. The values are assigned according to the actions of the agent.
In our model, we consider the different hockey leagues as possible states of the player. The key in our model is calculating the transition probability of a player to transition from one league to another. In this way, we can assign a reward function that will penalize the player if the transition is to a lower league level, and will positively reward the player if the transition is to an upper level league. In fact, the definition of a MDP is a tuple given by 𝑀=(𝑆,𝐴,𝑃,𝑅), where 𝑆 is the set of states of the agent (player), 𝐴 is the set of actions performed by the player, 𝑃 is the probability matrix, and 𝑅 is the set of rewards.
Since two of the most important elements in our model is the transition probability and the reward function, I am going to offer a more detailed explanation for each one of them.
- Transition probability:
We define transition as the change from one league to another displayed by a player. Then, the probability that the player will jump from one league to another is called transition probability.
To calculate the transition probability, we first need to order the historical data. In this way, we guarantee that the calculated probability corresponds to the transition between previous_league and next_league. We obtained an extended dataset from the of historical data for players that satisfy the following conditions: Active players in seasons 2015-2016 to 2019-2020; Players whose team was affiliated to a league in NorthAmerica; Players with minimum year of birth 1970.
Our data contains the transitions between the league n and the league n+1 for players that satisfy the conditions above. For the initial model, I kept three features in a new DataFrame: AgeInSeason,league_Level, and leagueName.
Using this data, we then proceed to calculate the transition probability matrix between two league levels, even if they are not consecutive. For this, I wrote a class called TransitionMatrix that allows us to calculate the probability of a player to move from one league to another.
![]()
Since individuals results are not meaningful, we have to calculate all the transition from all the retrieved players using the historical data. To store all the probabilities, we create a dictionary with keys as all the possible pairs between leagues (even if they make no sense at all!) and then calculate the cumulative probability with the cumulate_probabilities function.
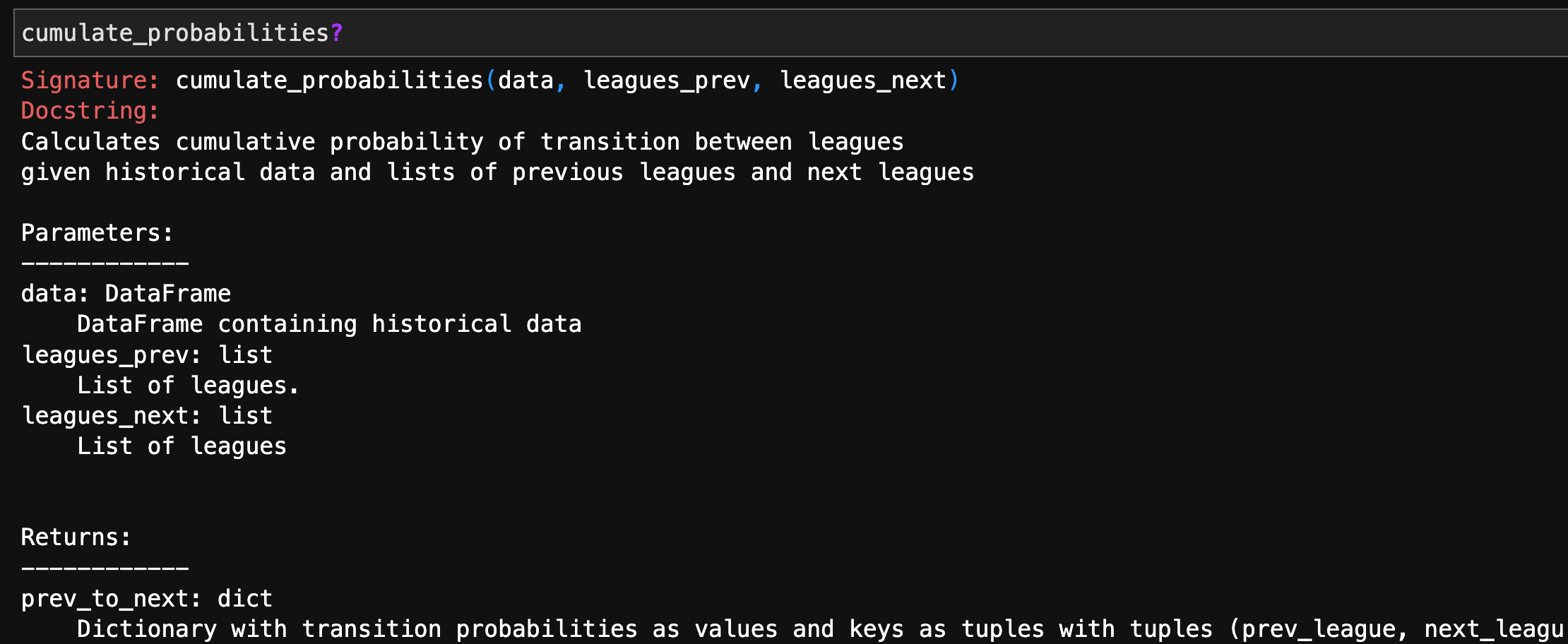
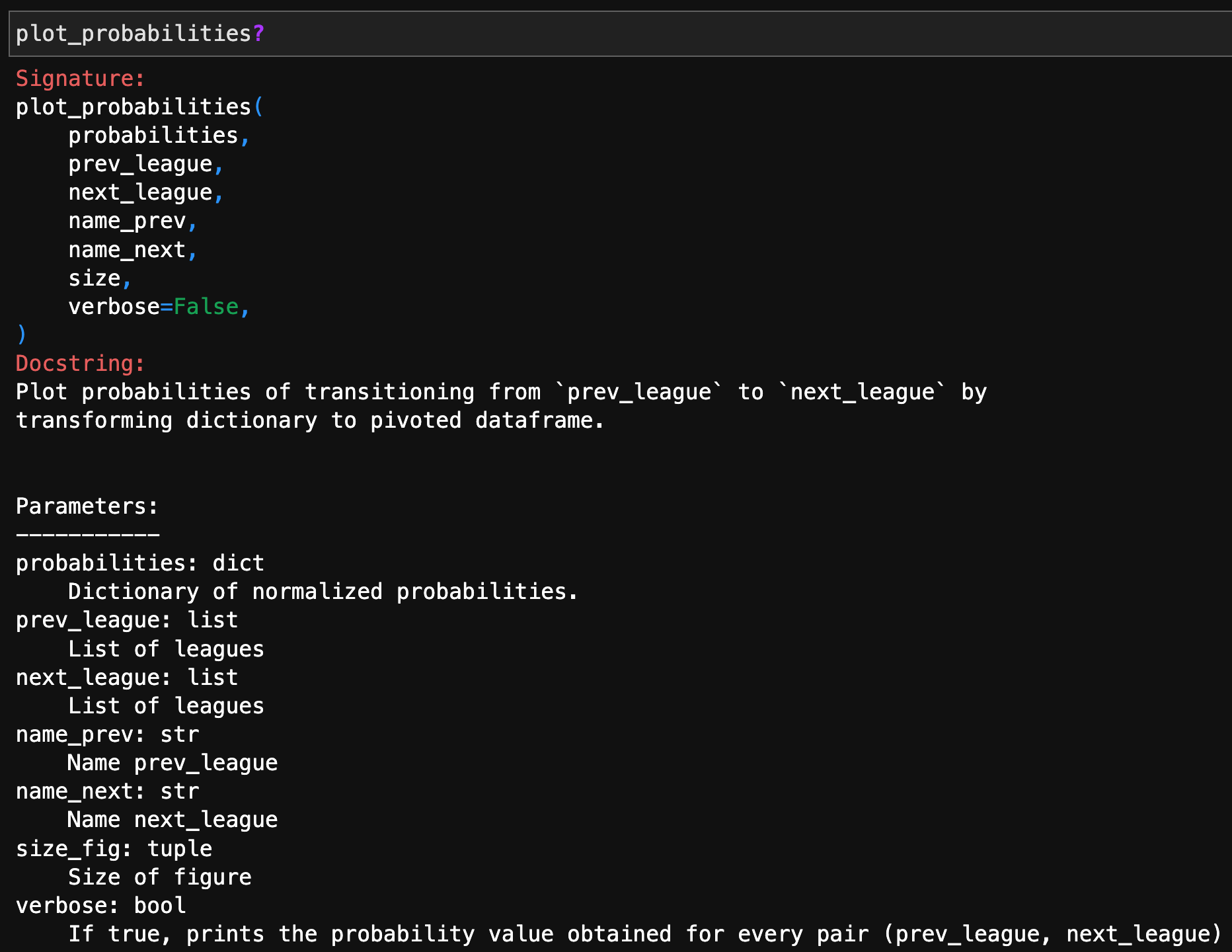
Then, we can plot the obtained probability with the plot_probabilities function.
For example, this is the obtained probability matrix for the transition between the college and the professional hockey leagues based on the selected players:
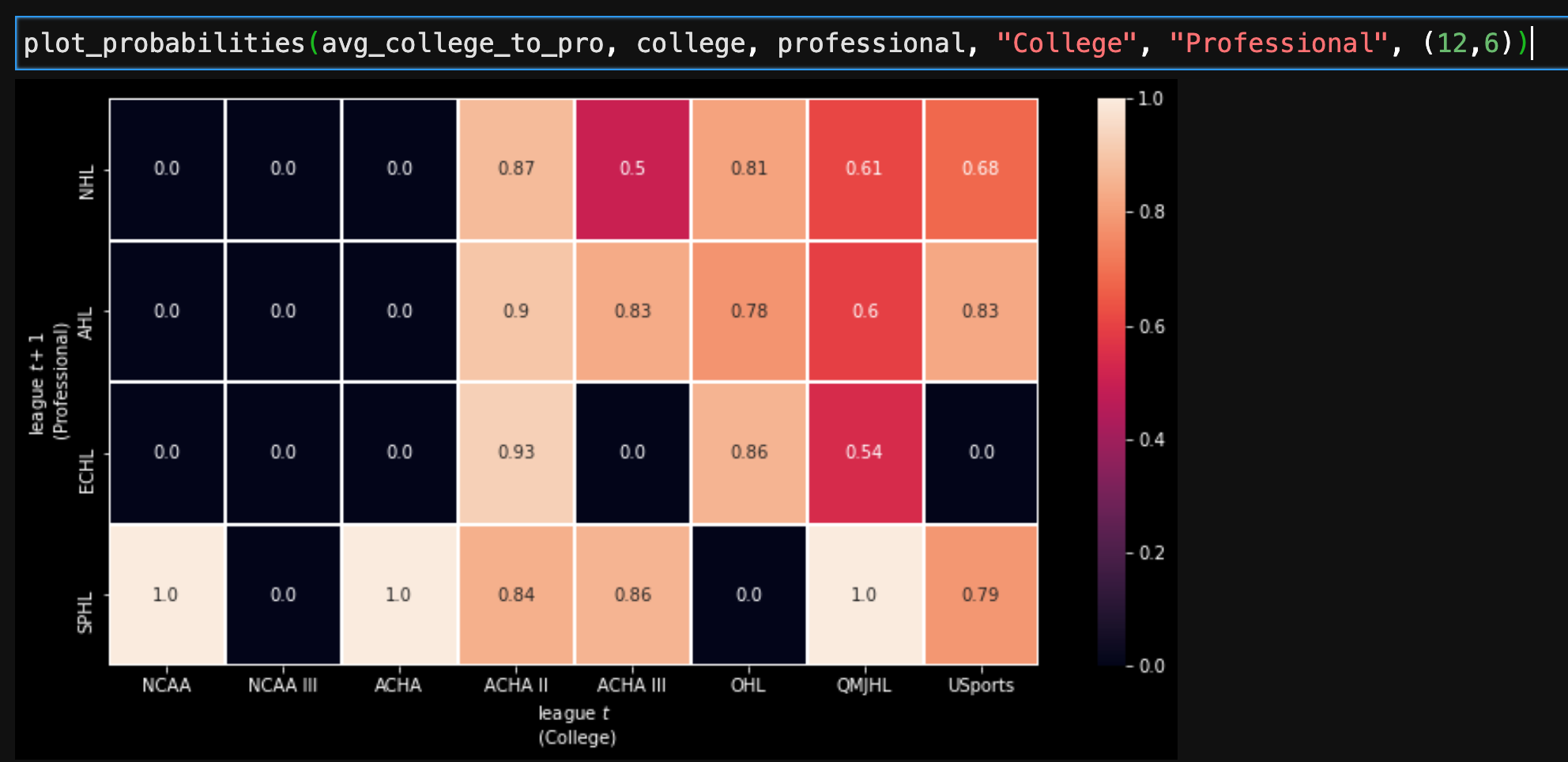
The plot above suggests that playing in the ACHA II or the QMJHl has a higher probability to transition to the SPHL, ECHL, AHL or NHL leagues. Hence, if a player manages to play in a ACHA II, III, QMJHL or USports, it has the highest probability to transition to the professional leagues.
Reward function
For our reward function, we considered the following ranking for league levels:
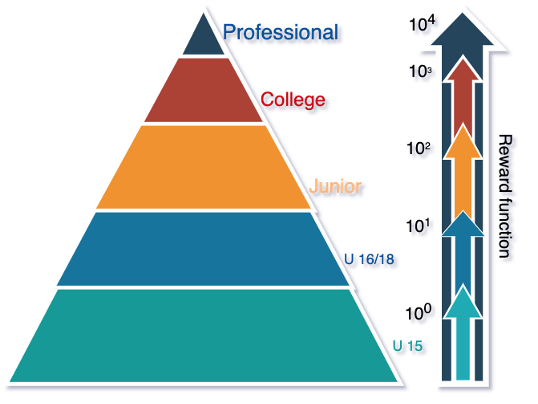
I proposed to calculate an exponential reward when transitioning to an upper league, with a penalty if the league is in the bottom of the list, among the possible leagues in that level. The ranking of the leagues by level goes according to the ordered lists:
ordered_professional = ['NHL', 'AHL', 'ECHL', 'SPHL']
ordered_college = ['NCAA', 'NCAA III', 'ACHA', 'ACHA II',
'ACHA III', 'OHL', 'QMJHL', 'USports']
ordered_junior = ['USHL', 'WHL', 'NAHL', 'AJHL', 'BCHL',
'OJHL', 'SJHL', 'CapJHL', 'KIJHL', 'EHL',
'NA3HL', 'EOJHL', 'GOJHL', 'USPHL Premier',
'USPHL Elite']
ordered_u_16_18 = ['T1EHL 18U', 'AEHL U18', 'QM18AAA',
'CSSHL U18', 'T1EHL 16UA', 'AEHL U16']
ordered_u_15_prep = ['USHS-Prep', 'AEHL U15', 'CSSHL U15',
'ALLIANCE U15', 'BC U15', 'NOHL U15']Next steps
-
To continue building the engine
The availability of libraries for reinforcement learning is currently very limited. The model here presented required a brand new engine to calculate probabilities. Although here we present an initial approach, it needs further improvement, in particular to tune the reward function considering a more complex set of parameters. -
To improve transition probability calculation
The next step is to calculate the transition probabilities as a function of the location of the player (feature placeOfBirth from the EliteProspects API). That would allow us to identify possible team targets that the player could focus on. After that, the probability could be further calculated by adding player statistics. -
To improve the reward function definition
This can be achieved by assessing the probability of the player getting/holding a scholarship, as a function of the league name, league level, player stats, and team. Finally, a function that takes into account the cost of joining a certain league could also improve the current RL - MDP model.
Deliverables
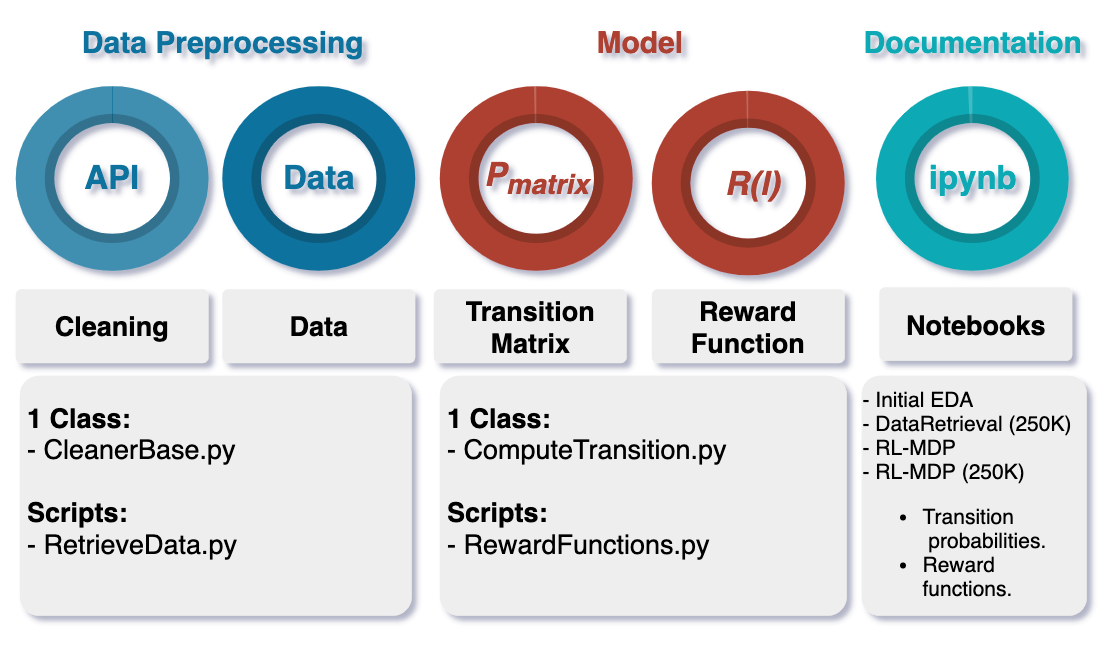
My deliverables during the Cybera Data Science Fellowship can be classified in three main groups: data processing, model building, and documentation.
Data Processing
To process the data extracted from the EliteProspects API, I wrote the CleanerBase.py class and the RetrieveData.py script that automates data retrieval and optimize data cleaning by splitting, dropping, and assigning keywords to obtain a simplified DataFrame.
Model Building
During the development of the model, I wrote the ComputeTransition.py class that calculates transitions between states given a Markov stochastic decission process by determining frequencies of events to then compute probabilities of the transition between hockey leagues. This class also includes a transition matrix object that derives the stochastic matrix of a Markov chain, to help in computing probabilities. I also delivered the RewardsFunction.py script that calculates the exponential reward function for every transition to an upper league.
Documentation
All the development was documented in four separate jupyter notebooks, identified by the assigned Agile story name. The content included in the notebook include a detailed explanation and a step-by-step description of the inital Exploratory Data Analysis (EDA), model building, and the results obtained with their respective data visualization in form of static heatmaps.
Conclusions
- The MDP model built for HockeyAI allows the calculation of transition probability matrix between two sets of leagues, not necessarily consecutive.
- In this project, I provided a class to compute transition matrices. This, in combination with the reward functions, helps to recommend a career path for hockey players.
- MDP models are a suitable approach to reach the goals from Hockey AI. The accuracy of this model depends on the size of the dataset (here used with 250K entries) and other factors such as the features used to calculate the transition probability between hockey leagues.
The Cybera fellowship was a very interesting and challenging experience. It offered an opportunity to work in a Data Science team to solve real-life problems.